- Học kỳ
- SP2026
- Thời Gian
- 9/5/26
- Loại tài liệu
- FE
BDI302c SP26 FE
1. (Choose 1 answer)
Which tool is used for transferring data between Hadoop and relational databases?
A. Flume
B. Sqoop
C. Pig
D. Hive
2. (Choose 1 answer)
Which step in the data science process involves transforming raw data into a format suitable for analysis?
A. Acquire
B. Analyze
C. Prepare
D. Report
3. (Choose 1 answer)
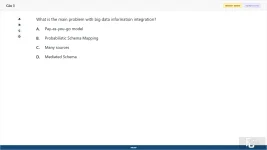
What is the main problem with big data information integration?
A. Pay-as-you-go model
B. Probabilistic Schema Mapping
C. Many sources
D. Mediated Schema
4. (Choose 1 answer)
What's the best way to explain personalized marketing powered by big data?
A. Being able to use personalized data from every single customer for personalized marketing needs
B. To obtain and use customer information for groups of consumers and utilize it for marketing needs
C. Marketing to each customer on an individual level and suiting to their needs
D. Personalized marketing addressing individual customer needs
5. (Choose 1 answer)
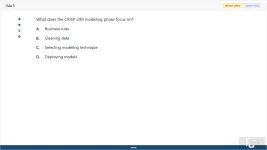
What does the CRISP-DM modeling phase focus on?
A. Business rules
B. Cleaning data
C. Selecting modeling technique
D. Deploying models
6. (Choose 1 answer)
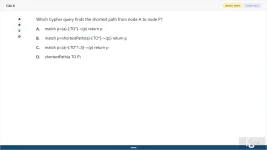
Which Cypher query finds the shortest path from node A to node P?
A. match p=(a)-[:TO*]->(p) return p
B. match p=shortestPath((a)-[:TO*]->(p)) return p
C. match p=(a)-[:TO*1..5]->(p) return p
D. shortestPath(a TO P)
7. (Choose 1 answer)
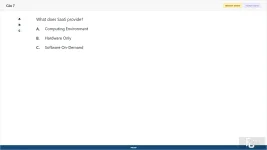
What does SaaS provide?
A. Computing Environment
B. Hardware Only
C. Software On-Demand
8. (Choose 1 answer)
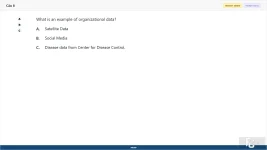
What is an example of organizational data?
A. Satellite Data
B. Social Media
C. Disease data from Center for Disease Control.
9. (Choose 1 answer)
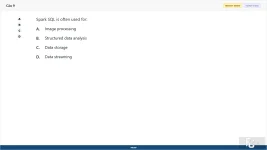
Spark SQL is often used for:
A. Image processing
B. Structured data analysis
C. Data storage
D. Data streaming
10. (Choose 2 answers)
Which of the following are the 2 core 'key player' problems that centrality analytics can address? (choose 2)
A. A set of nodes which can reach (almost) all other nodes
B. What is the shortest path through a network
C. Which nodes' removal will maximally disrupt the network
D. Which nodes have the highest ratio of out-degree nodes to in-degree nodes
11. (Choose 1 answer)
Use the following table named "user_table" to answer the problems. userId username email 1 admin [email protected] 2 h4xor [email protected] How would you go about querying the entire username column (however many)?
A. SELECT user_table FROM username
B. SELECT username FROM user_table
C. SELECT username FROM user_table WHERE userId=1
D. SELECT username FROM userId WHERE *
12. (Choose 1 answer)
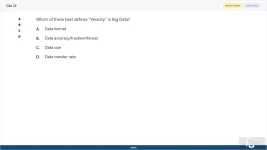
Which of these best defines "Veracity" in Big Data?
A. Data format
B. Data accuracy/trustworthiness
C. Data size
D. Data transfer rate
13. (Choose 1 answer)
When accessing the Pivot interface in Splunk, one can select a prebuilt data model to construct reports. Which of the following steps is crucial in ensuring the data model selected is relevant to the analytics needed?
A. Evaluate the fields within the data model against the report requirements
B. Check for any available data models created by other users
C. Choose the data model with the most fields available
D. Select the data model that was most recently updated
14. (Choose 1 answer)
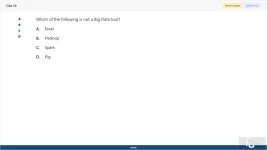
Which of the following is not a Big Data tool?
A. Excel
B. Hadoop
C. Spark
D. Pig
15. (Choose 1 answer)
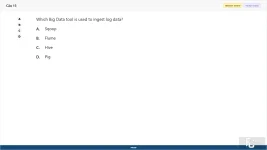
Which Big Data tool is used to ingest log data?
A. Sqoop
B. Flume
C. Hive
D. Pig
16. (Choose 1 answer)
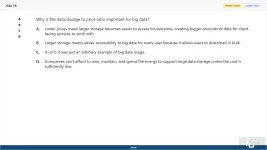
Why is the data storage to price ratio important for big data?
A. Lower prices mean larger storage becomes easier to access for everyone, creating bigger amounts of data for client-facing services to work with.
B. Larger storage means easier accessibility to big data for every user because it allows users to download in bulk.
C. It isn't; it was just an arbitrary example of big data usage.
D. Companies can't afford to own, maintain, and spend the energy to support large data storage unless the cost is sufficiently low.
17. (Choose 1 answer)
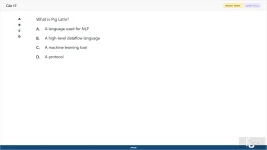
What is Pig Latin?
A. A language used for NLP
B. A high-level dataflow language
C. A machine learning tool
D. A protocol
18. (Choose 1 answer)
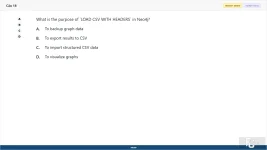
What is the purpose of `LOAD CSV WITH HEADERS` in Neo4j?
A. To backup graph data
B. To export results to CSV
C. To import structured CSV data
D. To visualize graphs
19. (Choose 1 answer)
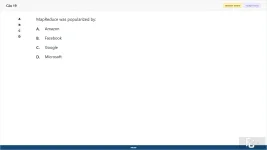
MapReduce was popularized by:
A. Amazon
B. Facebook
C. Google
D. Microsoft
20. (Choose 1 answer)
Which query calculates the weighted shortest path using distance in Neo4j?
A. MATCH (a)-[:TO]->(b) RETURN path
B. MATCH p = shortestPath((from)-[:TO*]->(to)) WITH REDUCE(dist = 0, rel in rels(p) | dist + toInt(rel.dist)) AS distance RETURN path, distance
C. MATCH-[r]-() RETURN REDUCE(dist=0, r in r | dist + 1)
D. MATCH p=(a)-[:TO*]->(b) RETURN reduce(p)
21. (Choose 1 answer)
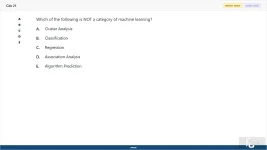
Which of the following is NOT a category of machine learning?
A. Cluster Analysis
B. Classification
C. Regression
D. Association Analysis
E. Algorithm Prediction
22. (Choose 1 answer)
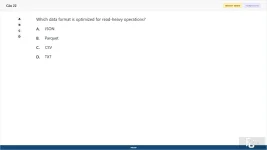
Which data format is optimized for read-heavy operations?
A. JSON
B. Parquet
C. CSV
D. TXT
23. (Choose 1 answer)
Consider the following generic statement: db.<collection>.find(<query filter>, <projection>).<cursor modifier>. Which part of the statement would reflect that of the SELECT statement in SQL as illustrated in the lecture?
A. <query filter>
B. <projection>
C. <cursor modifier>
D. <collection>
24. (Choose 1 answer)
Can you explain the key differences between data lakes and data warehouses?
A. Data lakes house raw data while data warehouses contain pre-formatted data.
B. Data lakes utilize hierarchical systems while data warehouses use object storage.
C. Data lakes contain only files, while data warehouses contain only databases.
D. None of the above.
25. (Choose 1 answer)
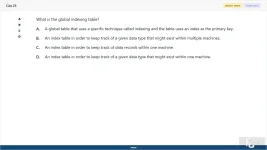
What is the global indexing table?
A. A global table that uses a specific technique called indexing and the table uses an index as the primary key.
B. An index table in order to keep track of a given data type that might exist within multiple machines.
C. An index table in order to keep track of data records within one machine.
D. An index table in order to keep track of a given data type that might exist within one machine.
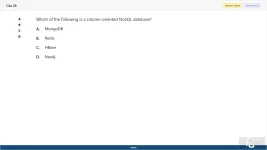
26. (Choose 1 answer)
Which of the following is a column-oriented NoSQL database?
A. MongoDB
B. Redis
C. HBase
D. Neo4j
27. (Choose 1 answer)
What is generally considered the initial stage in the process of developing a big data strategy?
A. Business Objectives
B. Organizational Buy-In
C. Build In-House Expertise
D. Collect Data
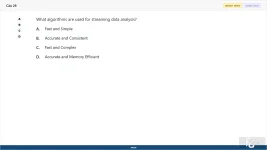
28. (Choose 1 answer)
What algorithms are used for streaming data analysis?
A. Fast and Simple
B. Accurate and Consistent
C. Fast and Complex
D. Accurate and Memory Efficient
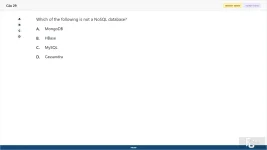
29. (Choose 1 answer)
Which of the following is not a NoSQL database?
A. MongoDB
B. HBase
C. MySQL
D. Cassandra
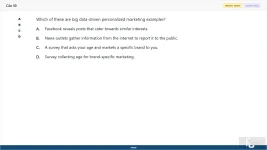
30. (Choose 1 answer)
Which of these are big data-driven personalized marketing examples?
A. Facebook reveals posts that cater towards similar interests.
B. News outlets gather information from the internet to report it to the public.
C. A survey that asks your age and markets a specific brand to you.
D. Survey collecting age for brand-specific marketing.
31. (Choose 1 answer)
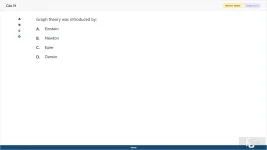
Graph theory was introduced by:
A. Einstein
B. Newton
C. Euler
D. Darwin
32. (Choose 1 answer)
Suppose a registration website creates data with the following fields for each person registered (note: if the user does not input a value, NULL is stored instead): Name, Date, Address, and Account Number. Which we have placed on the Account Number field for the end of year collection?
A. Account should have at most n digits
B. If we had n duplicate Account Numbers then we will remove n-1 duplicate fields
C. There are no constraints
D. Account Number should be unique
33. (Choose 1 answer)
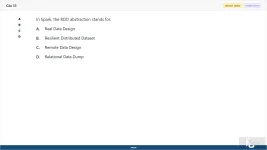
In Spark, the RDD abstraction stands for:
A. Real Data Design
B. Resilient Distributed Dataset
C. Remote Data Design
D. Relational Data Dump
34. (Choose 1 answer)
Why are trees useful for semi-structured data such as XML and JSON?
A. Computers can easily visualize the data with a tree structure
B. It is not always the case that XML and JSON can be represented as trees
C. Trees take advantage of the parent-child relationship of the data for easy navigation
D. They are only useful for XML data as tree-like structure is apparent with tags. While JSON does not contain a tree-like structure as it contains arrays
35. (Choose 1 answer)
What is one defining attribute of data that is being streamed?
A. Data is unbounded in size but requires only finite time and space to process it.
B. The data is finite and requires only finite time and space to process the data.
C. The data is unbounded in size, and the size determines the time and space of processing the data.
D. Data is finite in size, and size determines the time and space of processing the data.
36. (Choose 1 answer)
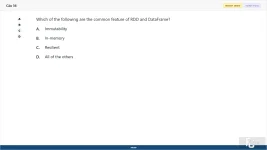
Which of the following are the common feature of RDD and DataFrame?
A. Immutability
B. In-memory
C. Resilient
D. All of the others
37. (Choose 1 answer)
Which MongoDB operator is used to filter documents based on specified conditions?
A. The $match operator
B. The $filter function
C. The $lookup operator
D. The $group operator
38. (Choose 1 answer)
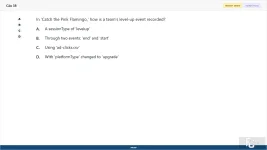
In 'Catch the Pink Flamingo,' how is a team's level-up event recorded?
A. A sessionType of 'levelup'
B. Through two events: 'end' and 'start'
C. Using 'ad-clicks.csv'
D. With 'platformType' changed to 'upgrade'
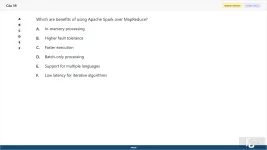
39. (Choose 4 answers)
Which are benefits of using Apache Spark over MapReduce?
A. In-memory processing
B. Higher fault tolerance
C. Faster execution
D. Batch-only processing
E. Support for multiple languages
F. Low latency for iterative algorithms
40. (Choose 1 answer)
What are data silos and why are they bad?
A. Data produced from an organization that is spread out. Bad because it creates unsynchronized and invisible data
B. A giant centralized database to house all the data production within an organization. Bad because it hinders opportunity for data generation
C. Highly unstructured data. Bad because it does not provide meaningful results for organizations
D. A giant centralized database to house all the data produces within an organization. Bad because it is hard to maintain as highly structured data
41. (Choose 1 answer)
What's the point of the BASE acronym?
A. To impose properties on a BDMS in order to guarantee certain results.
B. Enables stricter enforcement of ACID type design.
C. The same as ACID.
D. To overcome the CAP theorem.
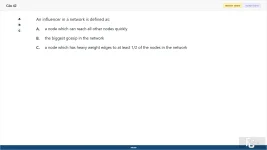
42. (Choose 1 answer)
An influencer in a network is defined as:
A. a node which can reach all other nodes quickly
B. the biggest gossip in the network
C. a node which has heavy weight edges to at least 1/2 of the nodes in the network
43. (Choose 1 answer)
What is a potential method to deal with too many data sources as mentioned in lecture?
A. Compare and weigh each source by their trustworthiness.
B. Randomly select a sample of sources to represent the various data sources.
C. Take less samples per tick.
D. None, the more the better.
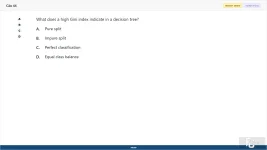
44. (Choose 1 answer)
What does a high Gini index indicate in a decision tree?
A. Pure split
B. Impure split
C. Perfect classification
D. Equal class balance
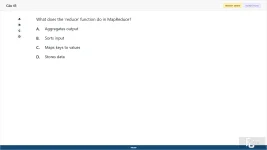
45. (Choose 1 answer)
What does the 'reduce' function do in MapReduce?
A. Aggregates output
B. Sorts input
C. Maps keys to values
D. Stores data
46. (Choose 1 answer)
What is the best description of personalized marketing enabled by big data?
A. Marketing to each customer on an individual level and suiting to their needs
B. Being able to use the data from each customer for marketing needs
C. Being able to obtain and use customer information for specific groups and utilize them for marketing needs
47. (Choose 1 answer)
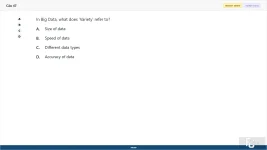
In Big Data, what does 'Variety' refer to?
A. Size of data
B. Speed of data
C. Different data types
D. Accuracy of data
48. (Choose 1 answer)
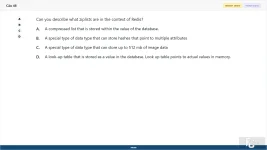
Can you describe what ziplists are in the context of Redis?
A. A compressed list that is stored within the value of the database.
B. A special type of data type that can store hashes that point to multiple attributes
C. A special type of data type that can store up to 512 mb of image data
D. A look-up table that is stored as a value in the database. Look up table points to actual values in memory.
49. (Choose 1 answer)
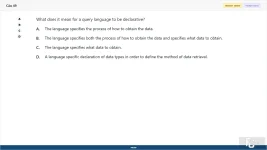
What does it mean for a query language to be declarative?
A. The language specifies the process of how to obtain the data.
B. The language specifies both the process of how to obtain the data and specifies what data to obtain.
C. The language specifies what data to obtain.
D. A language specific declaration of data types in order to define the method of data retrieval.
50. (Choose 1 answer)
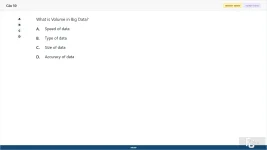
What is Volume in Big Data?
A. Speed of data
B. Type of data
C. Size of data
D. Accuracy of data
51. (Choose 1 answer)
How do you determine the classifier accuracy from the confusion matrix?
A. Divide the sum of the diagonal values in the confusion matrix by the sum of the off-diagonal values.
B. Divide the sum of all the values in the confusion matrix by the total number of samples.
C. Divide the sum of the diagonal values in the confusion matrix by the total number of samples.
D. Divide the sum of the off-diagonal values in the confusion matrix by the total number of samples.
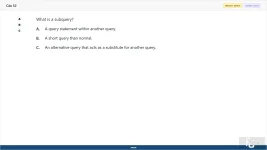
52. (Choose 1 answer)
What is a subquery?
A. A query statement within another query.
B. A short query than normal.
C. An alternative query that acts as a substitute for another query.
53. (Choose 1 answer)
You are working with a dataset in a Pandas DataFrame and need to calculate the mean of a column named sales. Which of the following code snippets would correctly calculate the mean?
A. df['sales'].mean()
B. mean(df['sales'])
C. df mean('sales')
D. sales mean()
54. (Choose 1 answer)
What is the difference between low level interfaces and high level interfaces?
A. Low level deals with storage and scheduling while high level deals with interactivity
B. Low level deals with interactivity while high level deals with storage and scheduling
55. (Choose 1 answer)
Which of the Vs results in increased algorithmic complexity (which can cause analyses to not be able to finish running in reasonable amounts of time)?
A. Valence
B. Velocity
C. Volume
D. Variety
56. (Choose 1 answer)
If I want to find the diameter of a graph, I should start by finding the shortest path between each set of nodes.
A. True
B. False
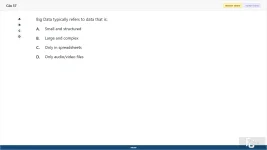
57. (Choose 1 answer)
Big Data typically refers to data that is:
A. Small and structured
B. Large and complex
C. Only in spreadsheets
D. Only audio/video files
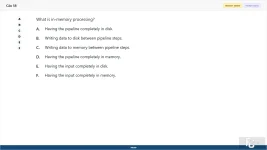
58. (Choose 1 answer)
What is in-memory processing?
A. Having the pipeline completely in disk.
B. Writing data to disk between pipeline steps.
C. Writing data to memory between pipeline steps.
D. Having the pipeline completely in memory.
E. Having the input completely in disk.
F. Having the input completely in memory.
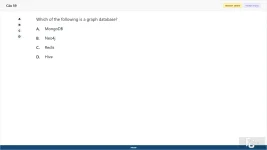
59. (Choose 1 answer)
Which of the following is a graph database?
A. MongoDB
B. Neo4j
C. Redis
D. Hive
60. (Choose 1 answer)
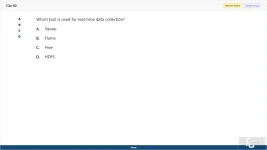
Which tool is used for real-time data collection?
A. Sqoop
B. Flume
C. Hive
D. HDFS
Đính kèm
-
 BDI302c SP26 FE_01.webp15.8 KB · Lượt xem: 0
BDI302c SP26 FE_01.webp15.8 KB · Lượt xem: 0 -
 BDI302c SP26 FE_02.webp18.2 KB · Lượt xem: 0
BDI302c SP26 FE_02.webp18.2 KB · Lượt xem: 0 -
 BDI302c SP26 FE_03.webp19.3 KB · Lượt xem: 0
BDI302c SP26 FE_03.webp19.3 KB · Lượt xem: 0 -
 BDI302c SP26 FE_04.webp39 KB · Lượt xem: 0
BDI302c SP26 FE_04.webp39 KB · Lượt xem: 0 -
 BDI302c SP26 FE_05.webp17.8 KB · Lượt xem: 0
BDI302c SP26 FE_05.webp17.8 KB · Lượt xem: 0 -
 BDI302c SP26 FE_06.webp22.7 KB · Lượt xem: 0
BDI302c SP26 FE_06.webp22.7 KB · Lượt xem: 0 -
 BDI302c SP26 FE_07.webp14.4 KB · Lượt xem: 0
BDI302c SP26 FE_07.webp14.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_08.webp16.6 KB · Lượt xem: 0
BDI302c SP26 FE_08.webp16.6 KB · Lượt xem: 0 -
 BDI302c SP26 FE_09.webp15.7 KB · Lượt xem: 0
BDI302c SP26 FE_09.webp15.7 KB · Lượt xem: 0 -
 BDI302c SP26 FE_10.webp33.4 KB · Lượt xem: 0
BDI302c SP26 FE_10.webp33.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_11.webp36.4 KB · Lượt xem: 0
BDI302c SP26 FE_11.webp36.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_12.webp17.3 KB · Lượt xem: 0
BDI302c SP26 FE_12.webp17.3 KB · Lượt xem: 0 -
 BDI302c SP26 FE_13.webp42.3 KB · Lượt xem: 0
BDI302c SP26 FE_13.webp42.3 KB · Lượt xem: 0 -
 BDI302c SP26 FE_14.webp13.1 KB · Lượt xem: 0
BDI302c SP26 FE_14.webp13.1 KB · Lượt xem: 0 -
 BDI302c SP26 FE_15.webp13.2 KB · Lượt xem: 0
BDI302c SP26 FE_15.webp13.2 KB · Lượt xem: 0 -
 BDI302c SP26 FE_16.webp46.1 KB · Lượt xem: 0
BDI302c SP26 FE_16.webp46.1 KB · Lượt xem: 0 -
 BDI302c SP26 FE_17.webp16.2 KB · Lượt xem: 0
BDI302c SP26 FE_17.webp16.2 KB · Lượt xem: 0 -
 BDI302c SP26 FE_18.webp19.9 KB · Lượt xem: 0
BDI302c SP26 FE_18.webp19.9 KB · Lượt xem: 0 -
 BDI302c SP26 FE_19.webp13.4 KB · Lượt xem: 0
BDI302c SP26 FE_19.webp13.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_20.webp33.6 KB · Lượt xem: 0
BDI302c SP26 FE_20.webp33.6 KB · Lượt xem: 0 -
 BDI302c SP26 FE_21.webp19.4 KB · Lượt xem: 0
BDI302c SP26 FE_21.webp19.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_22.webp14.2 KB · Lượt xem: 0
BDI302c SP26 FE_22.webp14.2 KB · Lượt xem: 0 -
 BDI302c SP26 FE_23.webp28 KB · Lượt xem: 0
BDI302c SP26 FE_23.webp28 KB · Lượt xem: 0 -
 BDI302c SP26 FE_24.webp33.7 KB · Lượt xem: 0
BDI302c SP26 FE_24.webp33.7 KB · Lượt xem: 0 -
 BDI302c SP26 FE_25.webp38.9 KB · Lượt xem: 0
BDI302c SP26 FE_25.webp38.9 KB · Lượt xem: 0 -
 BDI302c SP26 FE_26.webp15 KB · Lượt xem: 0
BDI302c SP26 FE_26.webp15 KB · Lượt xem: 0 -
 BDI302c SP26 FE_27.webp21.3 KB · Lượt xem: 0
BDI302c SP26 FE_27.webp21.3 KB · Lượt xem: 0 -
 BDI302c SP26 FE_28.webp19 KB · Lượt xem: 0
BDI302c SP26 FE_28.webp19 KB · Lượt xem: 0 -
 BDI302c SP26 FE_29.webp14.7 KB · Lượt xem: 0
BDI302c SP26 FE_29.webp14.7 KB · Lượt xem: 0 -
 BDI302c SP26 FE_30.webp32.3 KB · Lượt xem: 0
BDI302c SP26 FE_30.webp32.3 KB · Lượt xem: 0 -
 BDI302c SP26 FE_31.webp12.7 KB · Lượt xem: 0
BDI302c SP26 FE_31.webp12.7 KB · Lượt xem: 0 -
 BDI302c SP26 FE_32.webp42.5 KB · Lượt xem: 0
BDI302c SP26 FE_32.webp42.5 KB · Lượt xem: 0 -
 BDI302c SP26 FE_33.webp18.1 KB · Lượt xem: 0
BDI302c SP26 FE_33.webp18.1 KB · Lượt xem: 0 -
 BDI302c SP26 FE_34.webp40.2 KB · Lượt xem: 0
BDI302c SP26 FE_34.webp40.2 KB · Lượt xem: 0 -
 BDI302c SP26 FE_35.webp37.8 KB · Lượt xem: 0
BDI302c SP26 FE_35.webp37.8 KB · Lượt xem: 0 -
 BDI302c SP26 FE_36.webp16.8 KB · Lượt xem: 0
BDI302c SP26 FE_36.webp16.8 KB · Lượt xem: 0 -
 BDI302c SP26 FE_37.webp20.7 KB · Lượt xem: 0
BDI302c SP26 FE_37.webp20.7 KB · Lượt xem: 0 -
 BDI302c SP26 FE_38.webp22.1 KB · Lượt xem: 0
BDI302c SP26 FE_38.webp22.1 KB · Lượt xem: 0 -
 BDI302c SP26 FE_39.webp24.2 KB · Lượt xem: 0
BDI302c SP26 FE_39.webp24.2 KB · Lượt xem: 0 -
 BDI302c SP26 FE_40.webp49.3 KB · Lượt xem: 0
BDI302c SP26 FE_40.webp49.3 KB · Lượt xem: 0 -
 BDI302c SP26 FE_41.webp23.4 KB · Lượt xem: 0
BDI302c SP26 FE_41.webp23.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_42.webp22.8 KB · Lượt xem: 0
BDI302c SP26 FE_42.webp22.8 KB · Lượt xem: 0 -
 BDI302c SP26 FE_43.webp28.2 KB · Lượt xem: 0
BDI302c SP26 FE_43.webp28.2 KB · Lượt xem: 0 -
 BDI302c SP26 FE_44.webp16.8 KB · Lượt xem: 0
BDI302c SP26 FE_44.webp16.8 KB · Lượt xem: 0 -
 BDI302c SP26 FE_45.webp16.9 KB · Lượt xem: 0
BDI302c SP26 FE_45.webp16.9 KB · Lượt xem: 0 -
 BDI302c SP26 FE_46.webp32.7 KB · Lượt xem: 0
BDI302c SP26 FE_46.webp32.7 KB · Lượt xem: 0 -
 BDI302c SP26 FE_47.webp16.2 KB · Lượt xem: 0
BDI302c SP26 FE_47.webp16.2 KB · Lượt xem: 0 -
 BDI302c SP26 FE_48.webp36.3 KB · Lượt xem: 0
BDI302c SP26 FE_48.webp36.3 KB · Lượt xem: 0 -
 BDI302c SP26 FE_49.webp35.4 KB · Lượt xem: 0
BDI302c SP26 FE_49.webp35.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_50.webp14.9 KB · Lượt xem: 0
BDI302c SP26 FE_50.webp14.9 KB · Lượt xem: 0 -
 BDI302c SP26 FE_51.webp40.7 KB · Lượt xem: 0
BDI302c SP26 FE_51.webp40.7 KB · Lượt xem: 0 -
 BDI302c SP26 FE_52.webp18.9 KB · Lượt xem: 0
BDI302c SP26 FE_52.webp18.9 KB · Lượt xem: 0 -
 BDI302c SP26 FE_53.webp26.4 KB · Lượt xem: 0
BDI302c SP26 FE_53.webp26.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_54.webp25.8 KB · Lượt xem: 0
BDI302c SP26 FE_54.webp25.8 KB · Lượt xem: 0 -
 BDI302c SP26 FE_55.webp21.3 KB · Lượt xem: 0
BDI302c SP26 FE_55.webp21.3 KB · Lượt xem: 0 -
 BDI302c SP26 FE_56.webp15.9 KB · Lượt xem: 0
BDI302c SP26 FE_56.webp15.9 KB · Lượt xem: 0 -
 BDI302c SP26 FE_57.webp17.6 KB · Lượt xem: 0
BDI302c SP26 FE_57.webp17.6 KB · Lượt xem: 0 -
 BDI302c SP26 FE_58.webp29.4 KB · Lượt xem: 0
BDI302c SP26 FE_58.webp29.4 KB · Lượt xem: 0 -
 BDI302c SP26 FE_59.webp13.6 KB · Lượt xem: 0
BDI302c SP26 FE_59.webp13.6 KB · Lượt xem: 0 -
 BDI302c SP26 FE_60.webp13.1 KB · Lượt xem: 0
BDI302c SP26 FE_60.webp13.1 KB · Lượt xem: 0