- Học kỳ
- SP2026
- Thời Gian
- 9/5/26
- Loại tài liệu
- FE
AID301c SP26 FE
1. (Choose 1 answer)
What is the purpose of the classification_report in sklearn?
A. To visualize data
B. To summarize model performance
C. To preprocess data
D. To train a model
2. (Choose 1 answer)
In the script example-spark-submit.sh, what does the #!/bin/bash line indicate?
A. It specifies the script's name
B. It indicates the script is written in Python
C. It tells the system to use the Bash shell to execute the script
D. It is a comment and has no effect
3. (Choose 1 answer)
In the context of NLP, what does sentiment analysis refer to?
A. Analyzing the structure of sentences
B. Determining the emotional tone behind a series of words
C. Translating text from one language to another
D. Summarizing large documents
4. (Choose 3 answers)
Thinking with the lens of the scientific process, what would your next steps be if you wanted to decide where to open the next store for your sled business?
A. Start pulling sales and other data to create a business viability assessment for Vermont
B. Gather more data and repeat the snowfall experiment
C. Gather different data say snowfall by county and repeat the experiment
D. Start a business viability assessment for all three states
5. (Choose 1 answer)
Processing the corpus with the provided lemmatize_document reduces the total number of tokens to what percentage of the original?
A. 10-15%
B. 20-35%
C. 45-50%
D. 70-75%
E. 85-95%
6. (Choose 1 answer)
What is the first step in setting up the Watson Developer Cloud Python SDK?
A. Install the SDK
B. Create an IBM Cloud account
C. Create a resource for Natural Language Understanding
D. Download the tutorial files
7. (Choose 1 answer)
When you worked on model deployment case study, which modification to the ALS algorithm had the largest effect on model performance?
A. The explicit training vs implicit training comparison
B. The lambda or regularization parameter
C. The epsilon or scale parameter
D. The l1 vs l2 comparison
8. (Choose 1 answer)
When you compiled the JSON files into a single DataFrame or NumPy array, about how many days did the entire range of dates span?
A. 400
B. 450
C. 500
D. 600
E. 650
9. (Choose 1 answer)
Which library in Python is commonly used for reading and writing CSV files?
A. NumPy
B. Matplotlib
C. Pandas
D. SciPy
10. (Choose 1 answer)
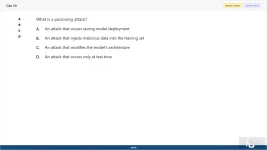
What is a poisoning attack?
A. An attack that occurs during model deployment
B. An attack that injects malicious data into the training set
C. An attack that modifies the model's architecture
D. An attack that occurs only at test time
11. (Choose 1 answer)
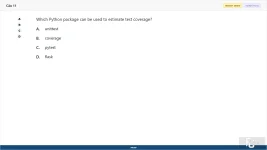
Which Python package can be used to estimate test coverage?
A. unittest
B. coverage
C. pytest
D. flask
12. (Choose 1 answer)
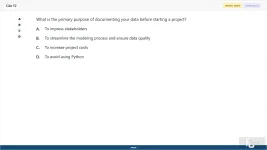
What is the primary purpose of documenting your data before starting a project?
A. To impress stakeholders
B. To streamline the modeling process and ensure data quality
C. To increase project costs
D. To avoid using Python
13. (Choose 1 answer)
What is a common issue with using accuracy as a metric for imbalanced classes?
A. It is always accurate.
B. It can be misleading.
C. It is the only metric available.
D. It does not consider false positives.
14. (Choose 1 answer)
The decision tree base models in random forests individually have high bias and low variance.
A. True
B. False
15. (Choose 1 answer)
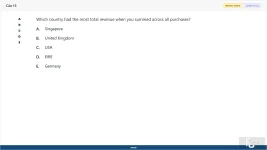
Which country had the most total revenue when you summed across all purchases?
A. Singapore
B. United Kingdom
C. USA
D. EIRE
E. Germany
16. (Choose 1 answer)
Which of the following is NOT a component of the confusion matrix?
A. True Negatives (TN)
B. False Positives (FP)
C. True Positives (TP)
D. Average Score (AS)
E. False Negatives (FN)
17. (Choose 1 answer)
Docker containers run a private file system that is isolated from the host and other containers. What is the suggested way to access notebooks and scripts from within the container?
A. tmpfs mount
B. use a named pipe
C. bind mounts
D. GitHub
E. volumes
18. (Choose 1 answer)
When you use Watson Services like Watson Natural Language Understanding via the Python SDK, what are the three items that need to be saved? These items are generally saved on a local machine and included in scripts and notebooks as imported variables.
A. service version, service API key, service JSON map
B. service URL, service JSON map, service API key
C. service API key, service version, service URL
D. service version, service IAMAuthenticator, service URL
E. service API key, service URL, service IAMAuthenticator
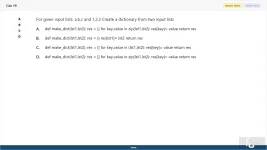
19. (Choose 1 answer)
For given input lists: a,b,c and 1,2,3 Create a dictionary from two input lists
A. def make_dict(lst1,lst2): res = {} for key,value in zip(lst1,lst2): res[key]= value return res
B. def make_dict(lst1,lst2): res = {} res[lst1]= lst2 return res
C. def make_dict(lst1,lst2): res = {} for key,value in (lst1,lst2): res[key]= value return res
D. def make_dict(lst1,lst2): res = [] for key,value in zip(lst1,lst2): res[key]= value return res
20. (Choose 1 answer)
What is the purpose of kubectl in kubernetes?
A. Automatic logging of requests and responses
B. A tool that makes it easy to run a single-node cluster locally
C. The primary node agent on each node, responsible for the processes running on that machine
D. The CLI for communicating with the kubernetes cluster
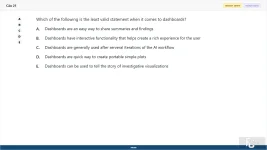
21. (Choose 1 answer)
Which of the following is the least valid statement when it comes to dashboards?
A. Dashboards are an easy way to share summaries and findings
B. Dashboards have interactive functionality that helps create a rich experience for the user
C. Dashboards are generally used after serveral iterations of the AI workflow
D. Dashboards are quick way to create portable simple plots
E. Dashboards can be used to tell the story of investigative visualizations
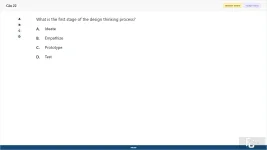
22. (Choose 1 answer)
What is the first stage of the design thinking process?
A. Ideate
B. Empathize
C. Prototype
D. Test
23. (Choose 1 answer)
Which of the following is NOT a factor that affects the time spent on data cleaning?
A. Team experience
B. Data quality
C. Project requirements
D. Company size
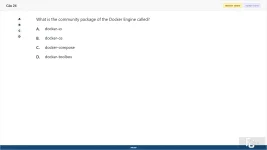
24. (Choose 1 answer)
What is the community package of the Docker Engine called?
A. docker-io
B. docker-ce
C. docker-compose
D. docker-toolbox
25. (Choose 2 answers)
Sparse matrices can be useful as a target destination for ETL, but what are the main caveats (choose one or more)?
A. You cannot convert directly from a numpy array to any of the scipy sparse matrices
B. NumPy linear algebra functions generally cannot be called directly
C. Saving to disk is not possible directly from a scipy sparse format
D. The train test splits need to be performed by hand with scipy sparse matrices
E. It is difficult to print to screen scipy sparse matrices directly
26. (Choose 1 answer)
There are many ways to carry out statistical inference. Which one method of the following is NOT used to compute estimates in the context of statistical inference.
A. Null Hypothesis Significance Testing (NHST)
B. Maximum Likelihood Estimation (MLE)
C. Markov Chain Monte Carlo (MCMC)
D. Expectation Maximization (EM)
E. Simulation via Permutations
27. (Choose 1 answer)
What does the term "trunk" refer to in the context of Continuous Integration?
A. A type of software bug
B. The main branch of code where all changes are merged
C. A deployment strategy
D. A testing framework
28. (Choose 1 answer)
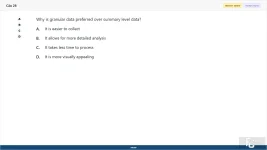
Why is granular data preferred over summary level data?
A. It is easier to collect
B. It allows for more detailed analysis
C. It takes less time to process
D. It is more visually appealing
29. (Choose 1 answer)
When embarking on a data science project, why do you ultimately want to format your data so that it can be housed in something like a Pandas DataFrame or NumPy Array?
A. DataFrames/Arrays most closely resemble tables in relational databases.
B. DataFrames/Arrays are the only structures in Python capable of holding significant amounts of data.
C. Nearly all modeling algorithms take input data in a tabular format analogous to format of DataFrames/Arrays.
D. All of the answers
30. (Choose 1 answer)
Which process model is known for its open standard and has been around since 1996?
A. OSEMN
B. CRISP-DM
C. Design Thinking
D. Agile
31. (Choose 1 answer)
What is a key principle of design thinking mentioned in the course?
A. Data collection
B. Observation and Reflection
C. Rapid prototyping
D. User testing
32. (Choose 1 answer)
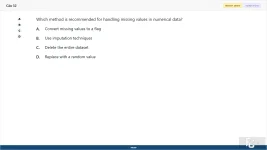
Which method is recommended for handling missing values in numerical data?
A. Convert missing values to a flag
B. Use imputation techniques
C. Delete the entire dataset
D. Replace with a random value
33. (Choose 1 answer)
Which of the following is a key aspect of applying data transformations?
A. Data collection
B. Iteration
C. Data visualization
D. Data storage
34. (Choose 1 answer)
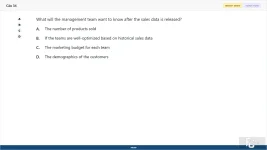
What will the management team want to know after the sales data is released?
A. The number of products sold
B. If the teams are well-optimized based on historical sales data
C. The marketing budget for each team
D. The demographics of the customers
35. (Choose 1 answer)
What is the primary purpose of dimensionality reduction in data science?
A. To increase the number of features
B. To simplify models and reduce computation time
C. To eliminate all data points
D. To create more complex models
36. (Choose 1 answer)
In the context of the AI workflow presented in these materials which of the following is not an example of a valid feedback loop?
A. Trying different data transformations on a given model
B. Returning to the data collection stage from transformations to reduce the number of transforms
C. Performing EDA on the data after a model has been deployed and data have been logged
D. Moving from the business opportunity and data collection to model iteration
E. Returning to discuss the business opportunity after a model has been deployed
37. (Choose 1 answer)
What is a key reason for using existing NLP APIs instead of building models from scratch?
A. They are always more accurate
B. They require less time and resources
C. They are easier to understand
D. They eliminate the need for data
38. (Choose 1 answer)
Which of the following is a common challenge when optimizing code for machine learning models?
A. Lack of available data
B. Difficulty in improving training time for large models
C. Inability to use multiple GPUs
D. Limited programming languages available
39. (Choose 1 answer)
If you have data with a large number of features and you are sure that it will take some time to train and tune the model, which approach is LEAST likely to result in a speed improvement during grid-searching?
A. In your pipeline use variance thresholding to limit the number of features
B. Use the Shuffle and split form of cross-validation
C. Use a randomized grid search form of cross validation
D. Randomly subset the data
E. Use PCA to reduce the dimensionality of the data before training
40. (Choose 1 answer)
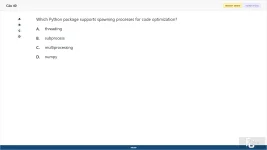
Which Python package supports spawning processes for code optimization?
A. threading
B. subprocess
C. multiprocessing
D. numpy
41. (Choose 1 answer)
Which of the following neural network architectures are most-commonly used for time-series analysis?
A. Multi-layer perceptron
B. Recurrent neural networks
C. Transfer learning
D. Convolutional neural network
E. Autoencoders
42. (Choose 1 answer)
A decision tree classifier is useful as a model for the AAVAIL subscriber churn data.
A. True
B. False
43. (Choose 1 answer)
What is the purpose of profiling in code optimization?
A. To write new algorithms from scratch
B. To identify which parts of the code are bottlenecks
C. To increase the number of processor cores
D. To reduce the amount of data used
44. (Choose 1 answer)
What type of data structures are used as standardized input to the interfaces in scikit-learn?
A. Lists and dictionaries
B. DataFrames and Series
C. NumPy arrays and SciPy sparse matrices
D. Strings and tuples
45. (Choose 1 answer)
Which command-line tool is used to interact with the Kubernetes API?
A. Kubelet
B. Kube CTL
C. Docker
D. Helm
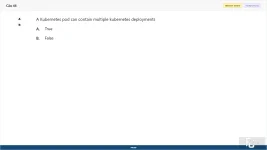
46. (Choose 1 answer)
A Kubernetes pod can contain multiple kubernetes deployments
A. True
B. False
47. (Choose 1 answer)
Docker images are the basis of containers. It is possible to pull an image from the registry and ask the Docker client to run a container based on that image. Some images are official while many others are user defined
A. True
B. False
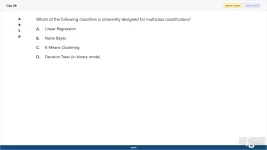
48. (Choose 1 answer)
Which of the following classifiers is inherently designed for multiclass classification?
A. Linear Regression
B. Naive Bayes
C. K-Means Clustering
D. Decision Trees (in binary mode)
49. (Choose 1 answer)
The.fit_transform method corresponds to which scikit-learn interface(s)?
A. Transformer, Estimator, Predictor
B. Transformer, Estimator
C. Estimator, Predictor
D. Transformer
E. Transformer, Predictor
50. (Choose 1 answer)
Which command is used to install the Watson Developer Cloud Python SDK?
A. pip install ibm-watson
B. pip install --upgrade ibm-watson
C. install ibm-watson
D. upgrade ibm-watson
Đính kèm
-
 AID301c SP26 FE_01.webp18.5 KB · Lượt xem: 0
AID301c SP26 FE_01.webp18.5 KB · Lượt xem: 0 -
 AID301c SP26 FE_02.webp25.7 KB · Lượt xem: 0
AID301c SP26 FE_02.webp25.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_03.webp25.2 KB · Lượt xem: 0
AID301c SP26 FE_03.webp25.2 KB · Lượt xem: 0 -
 AID301c SP26 FE_04.webp39.5 KB · Lượt xem: 0
AID301c SP26 FE_04.webp39.5 KB · Lượt xem: 0 -
 AID301c SP26 FE_05.webp21.3 KB · Lượt xem: 0
AID301c SP26 FE_05.webp21.3 KB · Lượt xem: 0 -
 AID301c SP26 FE_06.webp23.2 KB · Lượt xem: 0
AID301c SP26 FE_06.webp23.2 KB · Lượt xem: 0 -
 AID301c SP26 FE_07.webp28.9 KB · Lượt xem: 0
AID301c SP26 FE_07.webp28.9 KB · Lượt xem: 0 -
 AID301c SP26 FE_08.webp19.6 KB · Lượt xem: 0
AID301c SP26 FE_08.webp19.6 KB · Lượt xem: 0 -
 AID301c SP26 FE_09.webp15.8 KB · Lượt xem: 0
AID301c SP26 FE_09.webp15.8 KB · Lượt xem: 0 -
 AID301c SP26 FE_10.webp24.6 KB · Lượt xem: 0
AID301c SP26 FE_10.webp24.6 KB · Lượt xem: 0 -
 AID301c SP26 FE_11.webp15 KB · Lượt xem: 0
AID301c SP26 FE_11.webp15 KB · Lượt xem: 0 -
 AID301c SP26 FE_12.webp23.7 KB · Lượt xem: 0
AID301c SP26 FE_12.webp23.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_13.webp21.7 KB · Lượt xem: 0
AID301c SP26 FE_13.webp21.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_14.webp14.7 KB · Lượt xem: 0
AID301c SP26 FE_14.webp14.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_15.webp17.6 KB · Lượt xem: 0
AID301c SP26 FE_15.webp17.6 KB · Lượt xem: 0 -
 AID301c SP26 FE_16.webp20.7 KB · Lượt xem: 0
AID301c SP26 FE_16.webp20.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_17.webp25.9 KB · Lượt xem: 0
AID301c SP26 FE_17.webp25.9 KB · Lượt xem: 0 -
 AID301c SP26 FE_18.webp45.6 KB · Lượt xem: 0
AID301c SP26 FE_18.webp45.6 KB · Lượt xem: 0 -
 AID301c SP26 FE_19.webp36.5 KB · Lượt xem: 0
AID301c SP26 FE_19.webp36.5 KB · Lượt xem: 0 -
 AID301c SP26 FE_20.webp30.4 KB · Lượt xem: 0
AID301c SP26 FE_20.webp30.4 KB · Lượt xem: 0 -
 AID301c SP26 FE_21.webp41.2 KB · Lượt xem: 0
AID301c SP26 FE_21.webp41.2 KB · Lượt xem: 0 -
 AID301c SP26 FE_22.webp14.7 KB · Lượt xem: 0
AID301c SP26 FE_22.webp14.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_23.webp19.3 KB · Lượt xem: 0
AID301c SP26 FE_23.webp19.3 KB · Lượt xem: 0 -
 AID301c SP26 FE_24.webp16.9 KB · Lượt xem: 0
AID301c SP26 FE_24.webp16.9 KB · Lượt xem: 0 -
 AID301c SP26 FE_25.webp42.9 KB · Lượt xem: 0
AID301c SP26 FE_25.webp42.9 KB · Lượt xem: 0 -
 AID301c SP26 FE_26.webp33.5 KB · Lượt xem: 0
AID301c SP26 FE_26.webp33.5 KB · Lượt xem: 0 -
 AID301c SP26 FE_27.webp22.7 KB · Lượt xem: 0
AID301c SP26 FE_27.webp22.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_28.webp20.5 KB · Lượt xem: 0
AID301c SP26 FE_28.webp20.5 KB · Lượt xem: 0 -
 AID301c SP26 FE_29.webp43.2 KB · Lượt xem: 0
AID301c SP26 FE_29.webp43.2 KB · Lượt xem: 0 -
 AID301c SP26 FE_30.webp17.6 KB · Lượt xem: 0
AID301c SP26 FE_30.webp17.6 KB · Lượt xem: 0 -
 AID301c SP26 FE_31.webp18.6 KB · Lượt xem: 0
AID301c SP26 FE_31.webp18.6 KB · Lượt xem: 0 -
 AID301c SP26 FE_32.webp22.3 KB · Lượt xem: 0
AID301c SP26 FE_32.webp22.3 KB · Lượt xem: 0 -
 AID301c SP26 FE_33.webp17.9 KB · Lượt xem: 0
AID301c SP26 FE_33.webp17.9 KB · Lượt xem: 0 -
 AID301c SP26 FE_34.webp26.1 KB · Lượt xem: 0
AID301c SP26 FE_34.webp26.1 KB · Lượt xem: 0 -
 AID301c SP26 FE_35.webp23.9 KB · Lượt xem: 0
AID301c SP26 FE_35.webp23.9 KB · Lượt xem: 0 -
 AID301c SP26 FE_36.webp47.7 KB · Lượt xem: 0
AID301c SP26 FE_36.webp47.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_37.webp24.3 KB · Lượt xem: 0
AID301c SP26 FE_37.webp24.3 KB · Lượt xem: 0 -
 AID301c SP26 FE_38.webp26.2 KB · Lượt xem: 0
AID301c SP26 FE_38.webp26.2 KB · Lượt xem: 0 -
 AID301c SP26 FE_39.webp43.1 KB · Lượt xem: 0
AID301c SP26 FE_39.webp43.1 KB · Lượt xem: 0 -
 AID301c SP26 FE_40.webp17.5 KB · Lượt xem: 0
AID301c SP26 FE_40.webp17.5 KB · Lượt xem: 0 -
 AID301c SP26 FE_41.webp23.9 KB · Lượt xem: 0
AID301c SP26 FE_41.webp23.9 KB · Lượt xem: 0 -
 AID301c SP26 FE_42.webp14.1 KB · Lượt xem: 0
AID301c SP26 FE_42.webp14.1 KB · Lượt xem: 0 -
 AID301c SP26 FE_43.webp24.2 KB · Lượt xem: 0
AID301c SP26 FE_43.webp24.2 KB · Lượt xem: 0 -
 AID301c SP26 FE_44.webp22.6 KB · Lượt xem: 0
AID301c SP26 FE_44.webp22.6 KB · Lượt xem: 0 -
 AID301c SP26 FE_45.webp15.3 KB · Lượt xem: 0
AID301c SP26 FE_45.webp15.3 KB · Lượt xem: 0 -
 AID301c SP26 FE_46.webp12.8 KB · Lượt xem: 0
AID301c SP26 FE_46.webp12.8 KB · Lượt xem: 0 -
 AID301c SP26 FE_47.webp23.7 KB · Lượt xem: 0
AID301c SP26 FE_47.webp23.7 KB · Lượt xem: 0 -
 AID301c SP26 FE_48.webp20.6 KB · Lượt xem: 0
AID301c SP26 FE_48.webp20.6 KB · Lượt xem: 0 -
 AID301c SP26 FE_49.webp21.8 KB · Lượt xem: 0
AID301c SP26 FE_49.webp21.8 KB · Lượt xem: 0 -
 AID301c SP26 FE_50.webp20.9 KB · Lượt xem: 0
AID301c SP26 FE_50.webp20.9 KB · Lượt xem: 0